<!doctype html>
<html>
<body>
<h1>test.html here!</h1>
<script src="main.js"></script>
</body>
</html>
test.html
alert("Welcome!");
main.js
首先丢一个问题叭..像上面这样的东西是否可能产生xss呢...
看起来绝对不可能对吧...

首先介绍一下相对路径覆盖(RPO)这种攻击方式,在一些edge case里可以扩大xss的攻击面。这也不算新鲜了,网上的资料不是很多但也有不少师傅写得很详细了我这里就不过多赘述了..
这里就只简单讲一讲实现的原理和一些前置条件吧..
RPO的原理和产生的根本原因
浏览器在通过相对路径加载静态资源时(其实也不一定非要是静态资源啦..也可以劫持使用相对路径进行的跳转什么的,可能意义不大,看场景来),由于浏览器和部分webserver实现上的差异导致部分特殊构造的路径的语义出现歧义,攻击者可以通过构造特殊的url,来控制页面的base-path,让浏览器加载攻击者控制的任意静态资源。
浏览器和部分webserver实现上的差异
部分webserver(如nginx在遇到编码后的/(%2f)后会自动解码然后继续处理),就是说在url里构造/和%2f对于webserver来说没有差别,/foo/bar和/foo%2fbar对于webserver来说是同一个东西,即__foo目录下的bar文件__。
而对于大部分浏览器来说(我这边只实测了chrome和firefox,不知道ie什么情况),并不会自动解码%2f,唯一的用来作为目录分隔符的东西就是/本身(这里不考虑反斜杠\),所以对于浏览器来说/foo/bar是foo目录下的bar文件,而/foo%2fbar是根目录下的foo%2fbar文件,浏览器以这两种方式中任意一种去请求webserver得到的结果都是同一个东西,但是微妙的区别就在于使用/foo/bar去请求的话浏览器会把/foo目录作为相对路径的base-url,而对于第二种/foo%2fbar,浏览器会认为相对路径的base-url是根目录/.
此时我们假设/foo/bar文件是一个html,通过相对路径加载src="main.js"。对于正常的请求/foo/bar,相对路径的base-url是/foo所以浏览器会加载/foo/main.js。
相对的,如果通过/foo%2fbar去访问,虽然webserver返回的html是一样的,但是因为浏览器的实现不会decode %2f,而是把foo%2fbar整个当成了文件名,自然根目录/就被当成了相对路径的base-url,因此浏览器会去加载/main.js
进一步利用
在浏览器通过相对路径加载资源的过程中(base url+relative path),我们实际上可控的是base-url。
比如下面的payload/child/vul.php%3fvul=alert('RPO')%23/..%2ftest.html,这个在webserver看来和/child/not_exist/../test.html是一样的,就是/child/test.html的内容。
而对于浏览器来说这是/child/vul.php%3fvul=alert('RPO')%23/目录下的..%2ftest.html文件,其要通过相对路径加载的js就是/child/vul.php%3fvul=alert('RPO')%23/main.js,而/child/vul.php?vul=alert('RPO')的响应就是我们反射回来的payload
RPO的利用条件
- 目标页面使用相对路径加载资源(必须,且不能有base标签)
- 同源存在可控的存储的输入点(无论是否有针对 XSS 的过滤, 因为存储的只是 JS 而已) 或 url 被二次 decode(反射型输入点)
- webserver需能够把%2f解码为/并继续处理(文件系统路径 Nginx 默认配置下是会 decode %2f 的,但不会处理 proxy_pass (把 URI 按原样转发), 而Apache默认配置下 AllowEncodedSlashes的值是Off, 不存在不一致性也就无法利用)
exploit!
注意:取决于webserver配置
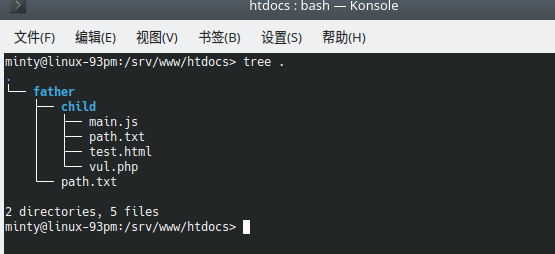
目录结构
main.js和test.html就是一开始那两个
<?php
parse_str(parse_url(urldecode($_SERVER[REQUEST_URI]), PHP_URL_QUERY), $_GET);
echo htmlentities($_GET['vul']);
vul.php
下面我来表演一下茴字的三种写法
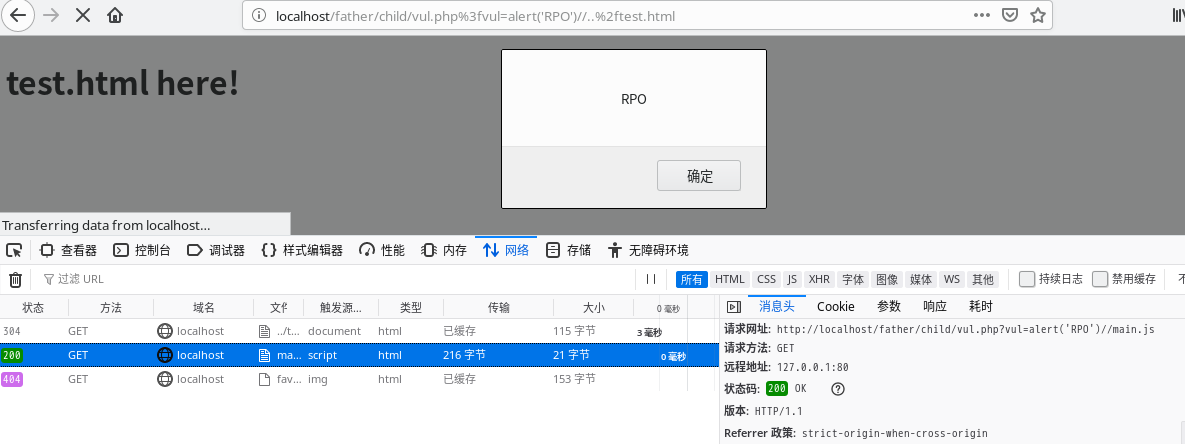
利用姿势1
Payload:
//localhost/father/child/vul.php%3fvul=alert('RPO')//..%2ftest.html

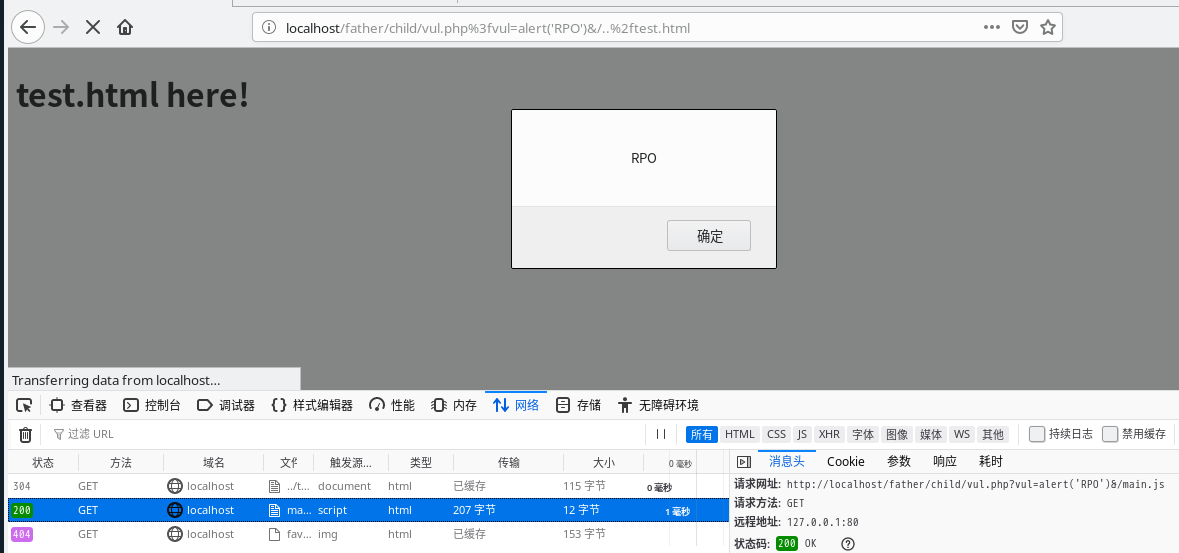
利用姿势2
Payload:
//localhost/father/child/vul.php%3fvul=alert('RPO')&/..%2ftest.html

利用姿势3
//localhost/father/child/vul.php%3fvul=alert('RPO')%23/..%2ftest.html
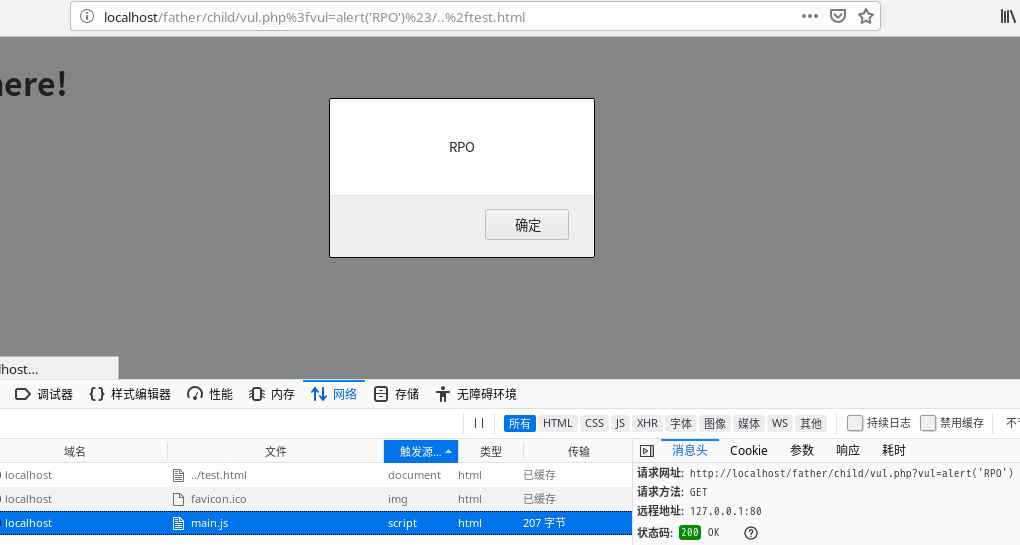
localhost/father/child/vul.php%3fvul=alert('RPO')#/..%2ftest.html,因为#后面的main.js只在本地处理,不会被包含在浏览器发送的request里,实际发送的请求见上图。

局限
为什么不能有base标签...
base标签已经指定了相对路径的默认base,
<head>
<base href="http://localhost/father/child/">
</head>
比如这里,无论我们怎么构造,浏览器加载静态资源时的行为就是base指定的base-path(和我们在url里构造出来的无关)+relative path(比如这里的main.js),两者我们都不可控,且似乎没有覆盖base标签指定的这个默认值的方法,所以和绝对路径一样无法利用。
要用反射型的 GET 的输入点来构造的话问号需编码,也就是说适用场景是受限的,需要 url 在解析过程中被二次解码,或者是 POST 的输入点也行(需要webserver 处理路径的优先级比匹配 php 高), 但对于 XSS 的场景来说似乎没有什么实际意义
如果同源有可以存储用户输入内容的地方(无论是否有针对一般 XSS 的过滤)可以忽略这条
Root Cause
不同组件不一致的 url 解析行为导致的语义不一致